Parallelization Workflow Pattern with Spring AI
This project demonstrates the implementation of the Parallelization Workflow pattern using Spring AI, enabling efficient concurrent processing of multiple Large Language Model (LLM) operations. The pattern is particularly useful for scenarios requiring parallel execution of LLM calls with automated output aggregation.
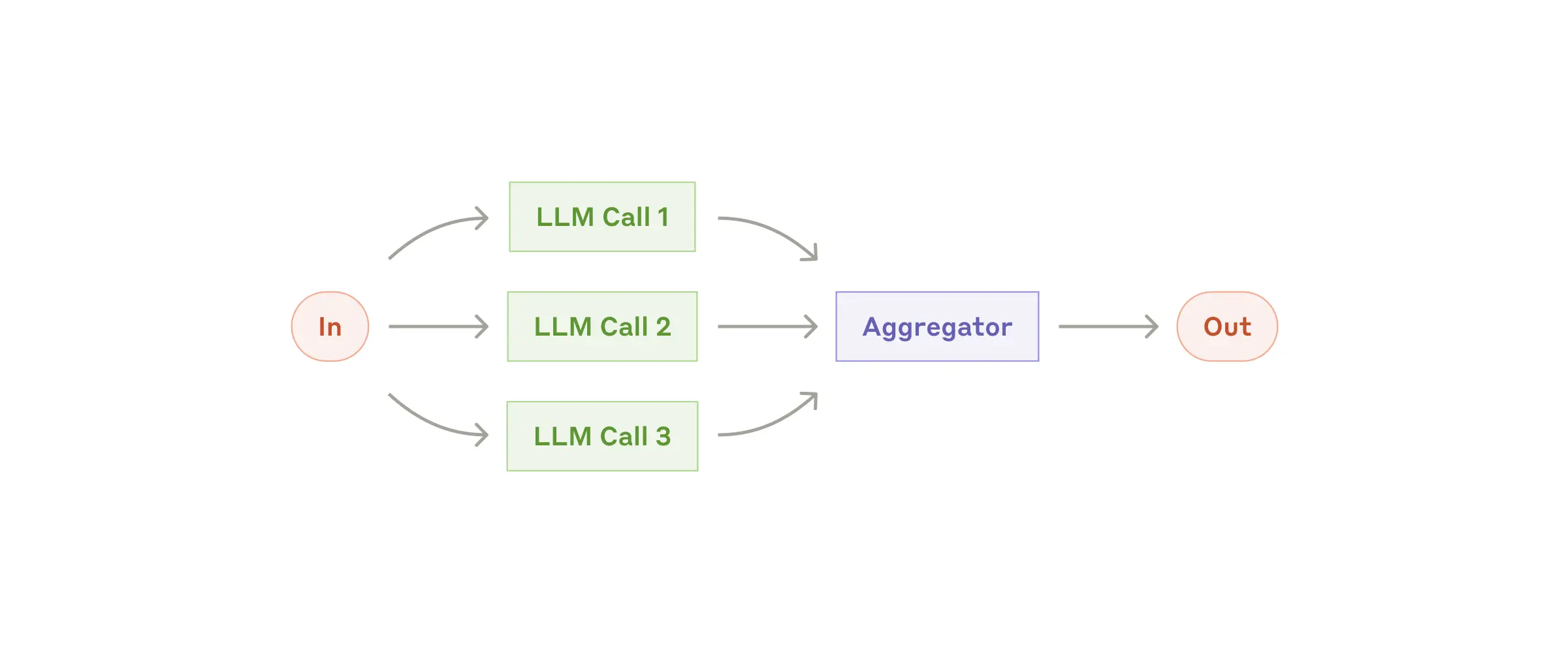
Overview
The Parallelization Workflow pattern manifests in two key variations:
- Sectioning: Decomposes complex tasks into independent subtasks for concurrent processing
- Voting: Executes identical prompts multiple times in parallel for diverse perspectives or majority voting
Key Benefits
- Improved throughput through concurrent processing
- Better resource utilization of LLM API capacity
- Reduced overall processing time for batch operations
- Enhanced result quality through multiple perspectives (in voting scenarios)
Prerequisites
- Java 17 or later
- Maven 3.6+
- Ollama (local LLM server)
Setup
- Clone the repository
- Build the project:
mvn clean install
Usage Example
Here's a basic example of using the Parallelization Workflow:
List<String> parallelResponse = new ParallelizationlWorkflow(chatClient)
.parallel(
"Analyze how market changes will impact this stakeholder group.",
List.of(
"Customers: ...",
"Employees: ...",
"Investors: ...",
"Suppliers: ..."
),
4
);
This example demonstrates parallel processing of stakeholder analysis, where each stakeholder group is analyzed concurrently.
Implementation Details
The ParallelizationlWorkflow class provides the core implementation with the following features:
- Fixed thread pool execution using
ExecutorService - Ordered result preservation matching input sequence
- Configurable number of worker threads
- Built-in error handling and resource management
- Integration with Spring AI's ChatClient
When to Use
- Processing large volumes of similar but independent items
- Tasks requiring multiple independent perspectives or validations
- Scenarios where processing time is critical and tasks are parallelizable
- Complex operations that can be decomposed into independent subtasks
Implementation Considerations
- Ensure tasks are truly independent to avoid consistency issues
- Consider API rate limits when determining parallel execution capacity
- Monitor resource usage (memory, CPU) when scaling parallel operations
- Implement appropriate error handling for parallel task failures
License
This project is licensed under the Apache License 2.0 - see the LICENSE file for details.